DRez is a modern rendering engine built with DirectX 12, serving as a complete rewrite of VRez with a stronger focus on performance, modularity, and modern rendering techniques.
The renderer implements a fully deferred rendering pipeline with Physically Based Rendering (PBR), Image-Based Lighting (IBL), Temporal Anti-Aliasing (TAA), shadow mapping, bindless rendering, and runtime shader compilation using SLANG.
Screenshots


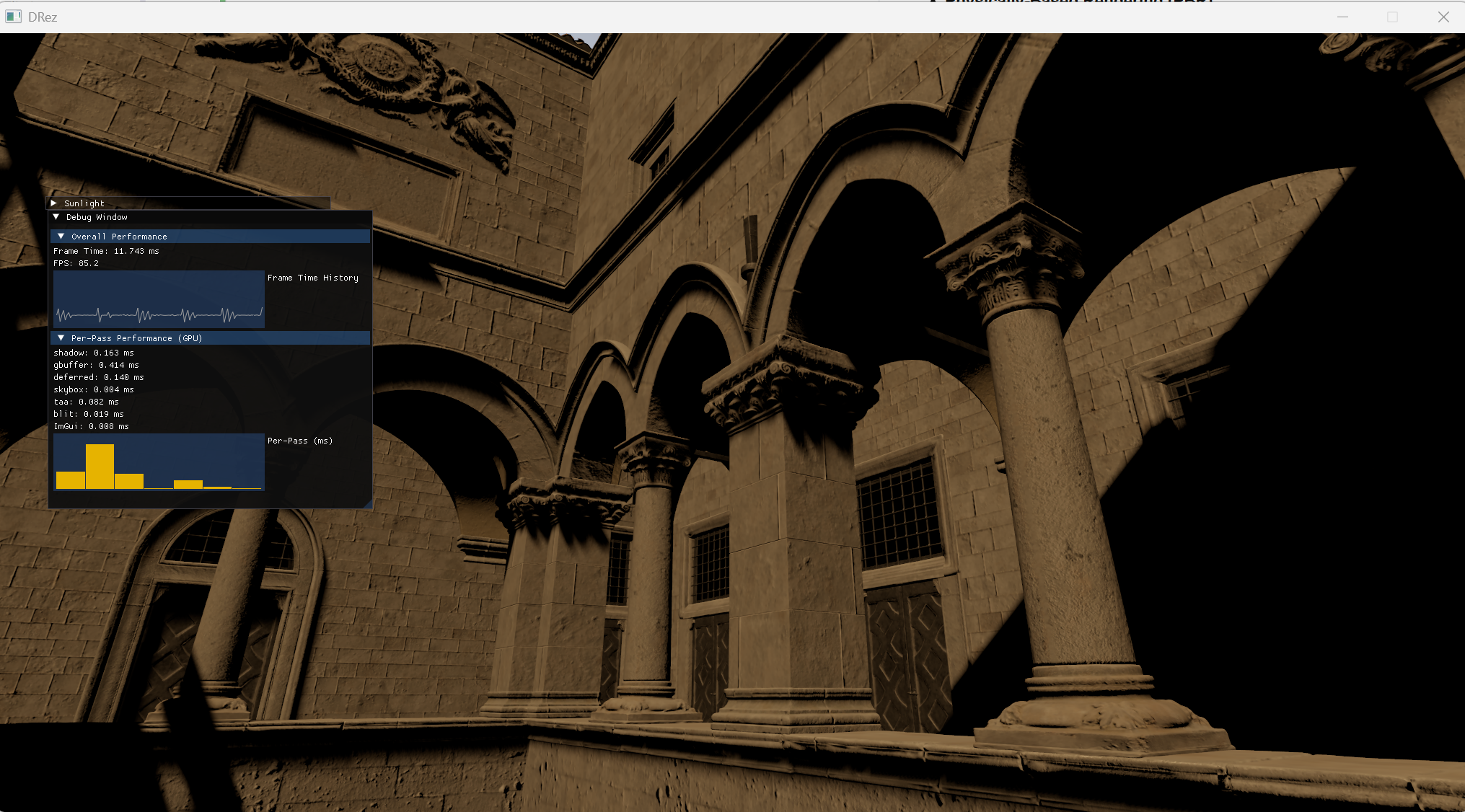
Rendering Features
The rendering backend is implemented using DirectX 12, while shaders are written and compiled at runtime using SLANG.
Mipmap Generation
Unlike Vulkan, DirectX 12 does not automatically generate mipmaps for textures. To address this, I implemented a compute shader pipeline that behaves similarly to vkCmdBlitImage, generating mip levels incrementally during texture loading.
A simplified snippet of the implementation is shown below:
void DXApp::GenerateMipmaps(DXTexture &texture, uint32_t srcSrvIndex) {
const uint16_t mipLevels = texture.GetMipLevels();
if (mipLevels <= 1) {
return;
}
// One UAV per non-base mip slice
std::vector<DXUnorderedAccessView> mipUavs;
mipUavs.reserve(mipLevels - 1);
std::ranges::for_each(std::views::iota(uint16_t{1}, mipLevels), [&](uint16_t m) {
const D3D12_UNORDERED_ACCESS_VIEW_DESC desc{
.Format = texture.GetFormat(),
.ViewDimension = D3D12_UAV_DIMENSION_TEXTURE2D,
.Texture2D = {.MipSlice = m, .PlaneSlice = 0},
};
mipUavs.push_back(CreateDXUnorderedAccessView(texture.GetResource(), desc));
});
ImmediateSubmit([&](ID3D12GraphicsCommandList *commandList) {
const std::vector<ID3D12DescriptorHeap *> heaps{m_descriptorHeap.Get()};
commandList->SetDescriptorHeaps(static_cast<uint32_t>(heaps.size()), heaps.data());
commandList->SetComputeRootSignature(m_mipmapPipeline.GetRootSignature());
commandList->SetPipelineState(m_mipmapPipeline.GetPipelineState());
// Initial barriers: mip 0 → sample state, mips 1..N-1 → UAV
std::vector<CD3DX12_RESOURCE_BARRIER> initBarriers;
initBarriers.reserve(mipLevels);
initBarriers.push_back(
CD3DX12_RESOURCE_BARRIER::Transition(
texture.GetResource(),
D3D12_RESOURCE_STATE_COPY_DEST,
D3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCE,
0
)
);
std::ranges::for_each(std::views::iota(uint16_t{1}, mipLevels), [&](uint16_t m) {
initBarriers.push_back(
CD3DX12_RESOURCE_BARRIER::Transition(texture.GetResource(), D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_UNORDERED_ACCESS, m)
);
});
commandList->ResourceBarrier(static_cast<uint32_t>(initBarriers.size()), initBarriers.data());
// Dispatch one downsample per mip pair: read mip i, write mip i+1
const uint64_t baseWidth = texture.GetWidth();
const uint32_t baseHeight = texture.GetHeight();
std::ranges::for_each(std::views::iota(uint16_t{0}, static_cast<uint16_t>(mipLevels - 1)), [&](uint16_t i) {
const uint32_t dstMip = static_cast<uint32_t>(i + 1);
const uint32_t dstWidth = std::max<uint32_t>(1, static_cast<uint32_t>(baseWidth) >> dstMip);
const uint32_t dstHeight = std::max<uint32_t>(1, baseHeight >> dstMip);
const shader_io::MipmapUniforms uniforms{
.srcIndex = srcSrvIndex,
.dstIndex = mipUavs[i].GetIndex(),
.srcMipLevel = i,
.padding = 0,
};
commandList->SetComputeRoot32BitConstants(0, sizeof(uniforms) / sizeof(uint32_t), &uniforms, 0);
const uint32_t groupX = static_cast<uint32_t>(std::ceil(static_cast<float>(dstWidth) / shader_io::kMipmapThreadX));
const uint32_t groupY = static_cast<uint32_t>(std::ceil(static_cast<float>(dstHeight) / shader_io::kMipmapThreadY));
commandList->Dispatch(groupX, groupY, 1);
// Hand off the just-written mip to the next iteration as a sample source
const auto b = CD3DX12_RESOURCE_BARRIER::Transition(
texture.GetResource(),
D3D12_RESOURCE_STATE_UNORDERED_ACCESS,
D3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCE,
dstMip
);
commandList->ResourceBarrier(1, &b);
});
// All mips end in NON_PIXEL_SHADER_RESOURCE; transition to PIXEL_SHADER_RESOURCE for rendering
std::vector<CD3DX12_RESOURCE_BARRIER> finalBarriers;
finalBarriers.reserve(mipLevels);
std::ranges::for_each(std::views::iota(uint16_t{0}, mipLevels), [&](uint16_t m) {
finalBarriers.push_back(
CD3DX12_RESOURCE_BARRIER::Transition(
texture.GetResource(),
D3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCE,
D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE,
m
)
);
});
commandList->ResourceBarrier(static_cast<uint32_t>(finalBarriers.size()), finalBarriers.data());
});
}
Deferred PBR Pipeline
A basic PBR pipeline with deferred rendering.
- Shadow Mapping (2048x2048)
- Render shadow-casting objects to shadow maps.
- Deferred Rendering
- G-Buffer Pass: write each mesh’s geometry information, such as world position, normal, and motion vector, to G-buffer textures.
- Lighting Pass: resolve the PBR and IBL equations using the G-buffer textures.
- Skybox Pass
- Render the skybox.
- Temporal Anti-Aliasing (TAA) Pass
- Resolve: use the velocity buffer from the G-Buffer Pass, the source color from the Skybox Pass, and the history color from the last frame’s TAA result to resolve the target.
- Jitter: use the Halton sequence to compute multiple sub-pixel samples across frames.
- Tonemapping
- HDR to LDR conversion.

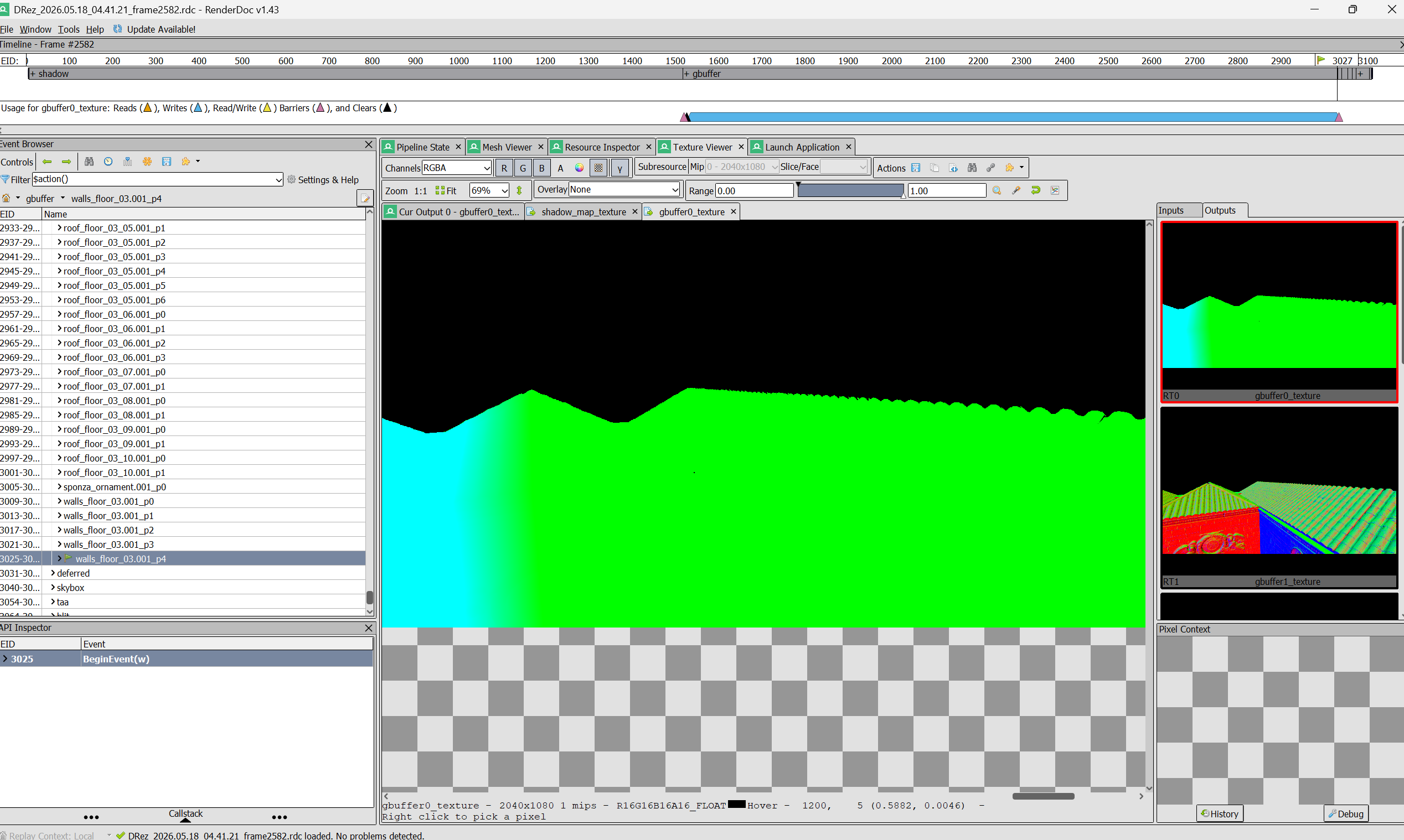
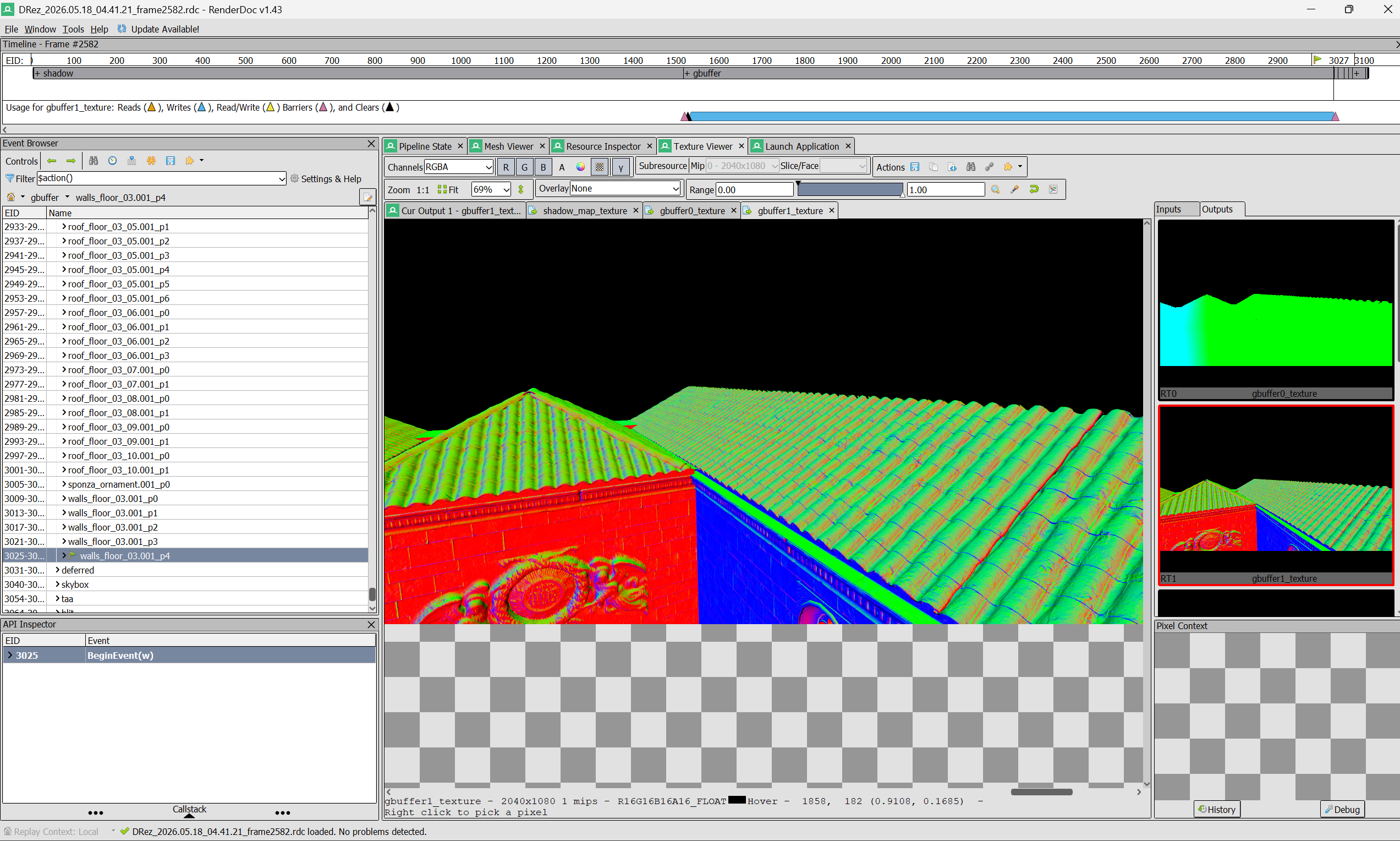
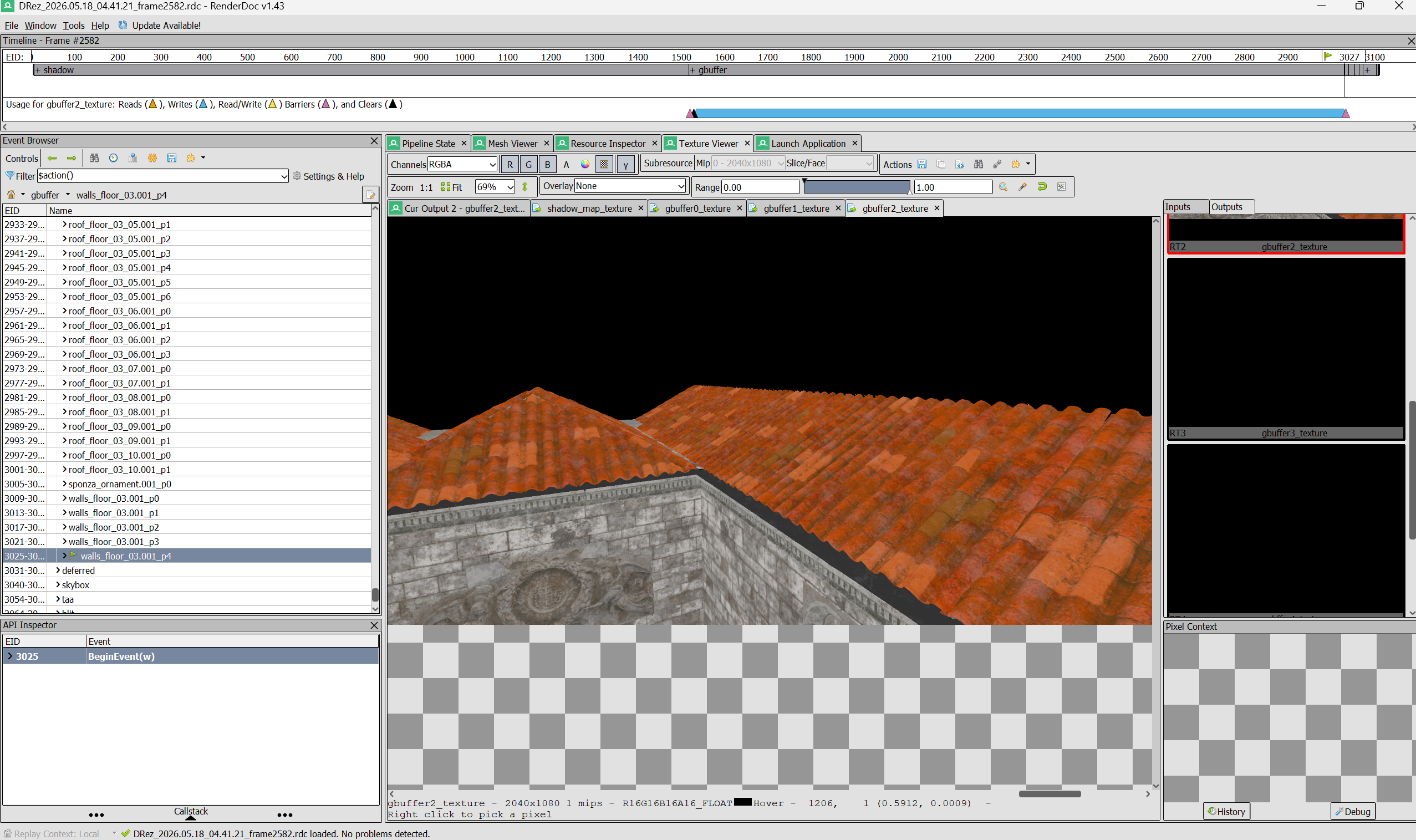
 TAA off (left) vs TAA on (right)
TAA off (left) vs TAA on (right)
Improvement
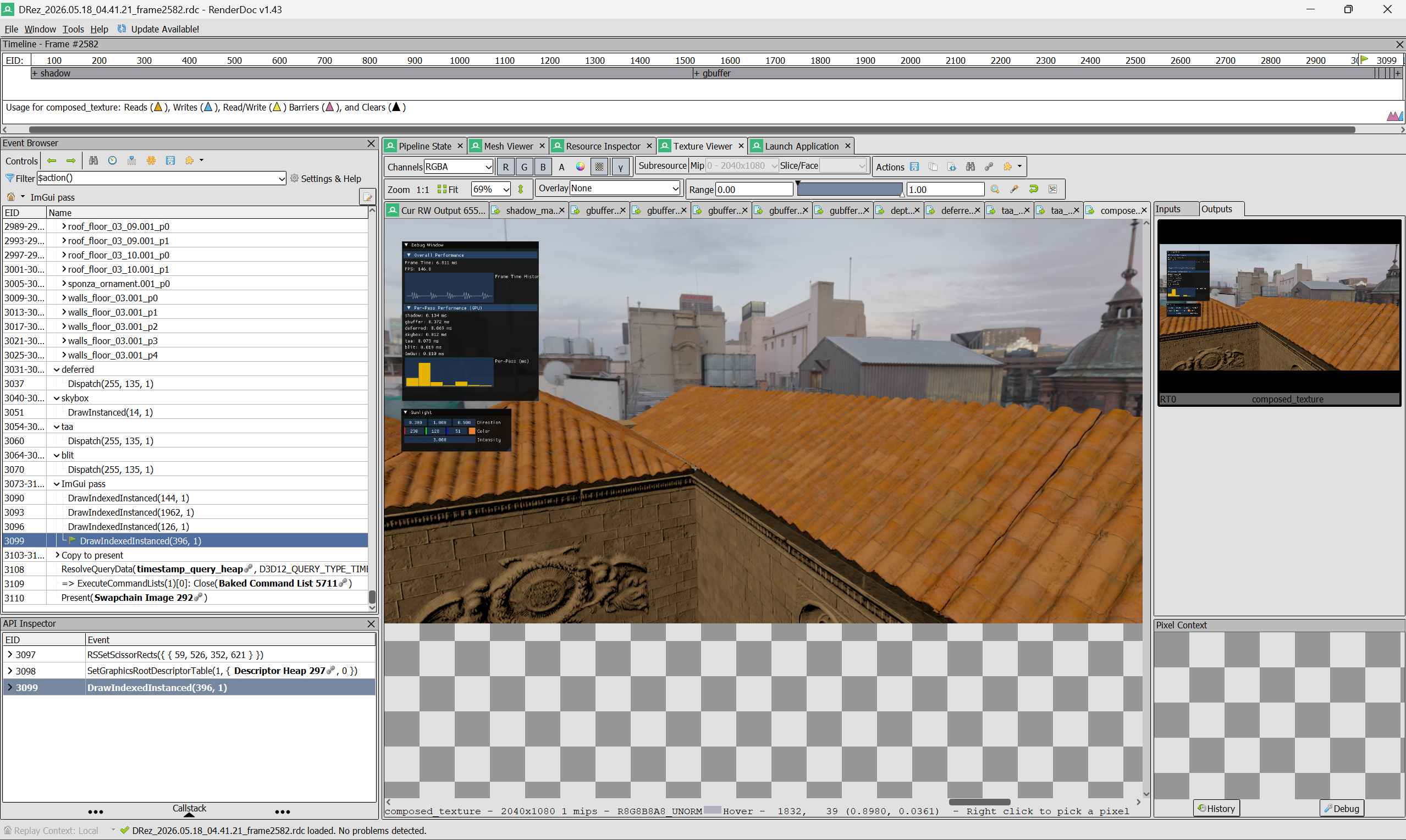
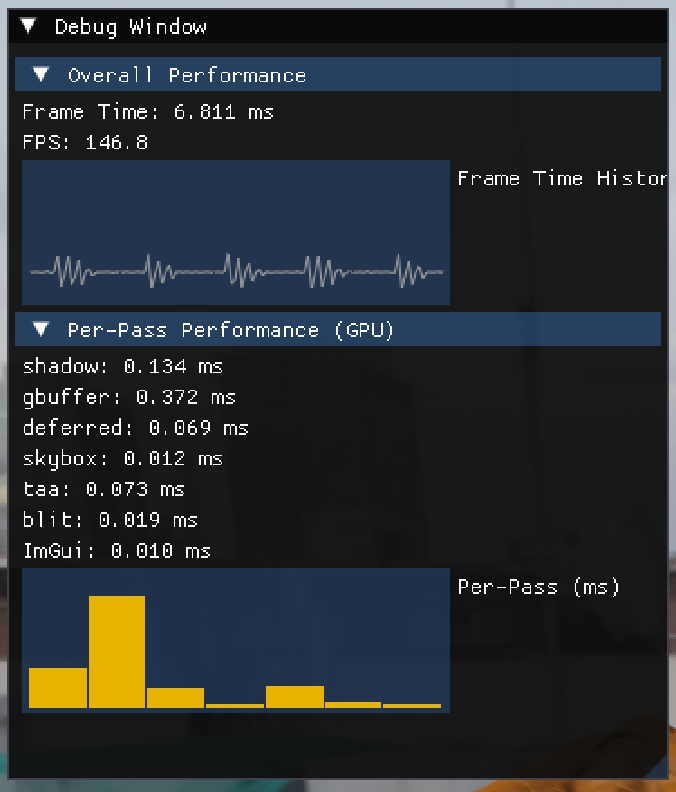
GPU Debugging and Profiling
- Integrated the D3D12 PIX event API to show resource and pass names in RenderDoc.
- Enabled timestamp queries to show each pass’s execution time.
Bindless Descriptors
All GPU resources are stored inside a global CBV/SRV/UAV descriptor heap. Instead of rebinding descriptors for every draw call, shaders receive resource indices through root constants and dynamically access resources through descriptor handles.
This approach enables:
- Reduced descriptor rebinding overhead
- More scalable resource management
- Flexible shader resource access
- Vertex pulling workflows
The following snippet demonstrates bindless resource access inside shaders:
const StructuredBuffer<shader_io::InstanceInfo> instances =
(DescriptorHandle<StructuredBuffer<shader_io::InstanceInfo>>)uint2(pushConstants.instancesIndex, 0);
const StructuredBuffer<shader_io::MeshInfo> meshes =
(DescriptorHandle<StructuredBuffer<shader_io::MeshInfo>>)uint2(pushConstants.meshesIndex, 0);
const shader_io::GbufferInfo gbufferInfo =
((DescriptorHandle<StructuredBuffer<shader_io::GbufferInfo>>)uint2(pushConstants.gbufferInfoIndex, 0))[0];
GLTF Asset Pipeline
The renderer uses the glTF format instead of OBJ files to support hierarchical scene structures and more modern asset workflows.
To improve loading performance for large scenes such as Sponza:
- Vertex data is uploaded as a single combined buffer resource.
- Texture uploads are batched together instead of uploaded individually.
This significantly reduces upload overhead and improves initialization performance.
To Improve
We can see from the per-pass performance that the G-Buffer Pass currently takes most of the frame time, because it draws every mesh from the GLTF scene file. Here are some thoughts I have on improving the performance:
- Batch identical meshes:
DrawIndexedInstancedis currently called once per mesh, but there are many repeated meshes in the scene. UsingSV_InstanceIDand a base instance to index intoInstanceInfowould collapse N draws of the same mesh into one and significantly improve performance. - Frustum Culling: Sponza is a large scene, and many meshes are off screen. Frustum culling would skip those meshes and improve performance.